Building my first AI Agent - Part 1: The Chat Relay
Hello, again!
It's been a while since the last time I posted. Holidays, sickness and a crazy work situation got in the way. But now I have more time to finish the project I claimed I would do last year. I tweaked a bit of the original scope but the goal is the same. Create an AI agent that helps me understand how agentic workflows work under the hood, and maybe help me create my own assistant that can run locally in my home...but that last one is a stretch goal.
Without further ado, let's jump into it.
Claude to the rescue
For this project, I wanted a nice TUI to be able to chat with the LLM, but I'm not here to learn ratatui (at least not this time!). So I prompted Claude to build a quick chat interface.
This interface can send messages, show the chat history and scroll through previous messages. Simple, nice and clean; that way I can focus on the important pieces of the project.
Important disclaimer: I think AI is a useful tool, but for projects like this where you want to learn how things work, it's better to code by hand the pieces you really want to understand. I used Claude for the boilerplate (like the TUI) and to help me understand Rust concepts I'm not yet an expert on.
LLM Providers
The first step is to check the API references for some of the popular AI providers. Since Gemini is free (albeit with very low limits), I decided to give that a try and write a quick client for it.
The way I decided to structure this is that we have an Agent component that will hide the different interfaces providers have. I found out that Gemini, Anthropic, Ollama and OpenAI use different ways to represent messages, roles and other parameters.
Roles, for example: while the basics are user and assistant, Gemini uses model instead of assistant. Anthropic, on the other hand, doesn't expose a system role in the messages array — the system prompt is passed as a separate parameter in the request body.
Messages were also different, Gemini being the most unusual of the bunch. For example, most providers return a list of messages with a role and content, but Gemini has the concept of candidates which, depending on your configuration, can return multiple answers with different scores. None of that is needed for my experiment.
With all this in mind, I decided that having the Agent component that abstracts away the provider interfaces was the right call.
Basic structure
For roles, I am using what I believe are the 3 basic ones: system, user and assistant. This is what my internal implementation is using.
I'm using rename here so that the serializer/deserializer can correctly parse the JSON returned from the providers, as they use lowercase but Rust enums use PascalCase by default.
#[derive(Serialize, Deserialize, Debug, Clone)] pub enum Role { #[serde(rename = "system")] System, #[serde(rename = "user")] User, #[serde(rename = "assistant")] Assistant, }
The Message struct is equally minimal — just a role and the text content.
#[derive(Serialize, Deserialize, Debug, Clone)] pub struct Message { pub role: Role, pub text: String, }
With the basic types defined, I proceeded to create the Agent components. Since there are only a handful of providers, I'm using an enum to keep things simple and avoid dealing with dyn trait shenanigans for now.
I also defined an Llm trait that each provider must implement. For now it only takes the message history.
The Agent enum also implements Llm, so callers don't need to care whether they're talking to a concrete provider or the enum wrapper. I could have skipped this for Agent, but it's a small cost and might come in handy if I switch to dyn polymorphism later.
pub enum Agent { Gemini(GeminiLlm), Ollama(OllamaLlm), } pub trait Llm { async fn generate(&self, messages: &[Message]) -> Result<Message>; } impl Llm for Agent { async fn generate(&self, messages: &[Message]) -> Result<Message> { match self { Agent::Gemini(a) => a.generate(messages).await, Agent::Ollama(a) => a.generate(messages).await, } } }
Finally, as you might know, LLMs are stateless services — they take the entire conversation on each call and generate the next message. So we have to keep track of the history ourselves. I went for a Chat struct that holds a vector of messages and the agent we are currently using.
Chat has a send method that appends the user's message to the history, calls the agent, and appends the response. If the agent errors out, it rolls back the last message so we only ever store successful exchanges.
pub struct Chat { history: Vec<Message>, agent: Agent, } impl Chat { pub fn new(agent: Agent) -> Self { Self { history: vec![], agent, } } pub async fn send(&mut self, text: &str) -> Result<String> { self.history.push(Message { role: Role::User, text: text.to_string(), }); let response = self.agent.generate(&self.history).await; match response { Ok(response_message) => { let response_text = response_message.text.clone(); self.history.push(response_message); Ok(response_text) } Err(e) => { self.history.pop(); Err(e) } } } }
An example of a provider implementation
OK, we have the UI, we have the internal components to track the conversation and the agent connection. Now we need to actually call the provider and have it all working end to end.
I implemented Gemini first since it's the only provider that currently supports a free tier. However, during my tests I ended up hitting the rate limit way too soon. While I could keep switching models, I decided Ollama was the way to go while I develop this.
The Ollama HTTP interface requires you to send the model, a list of messages, and in my case a boolean to turn off streaming. I didn't want to deal with streaming right now — I'm focused on the parts that get this working first.
The response from Ollama is basically just a single message instance, super simple. And the message struct requires only a role and the content of the message.
For the role, it supports system, user, assistant and tool. I decided to create a new OllamaRole enum to avoid polluting the internal one with Ollama-specific details — the tool role doesn't appear to be standard across other providers.
#[derive(Serialize, Deserialize, Debug)] struct OllamaRequest { model: String, messages: Vec<OllamaMessage>, stream: bool, } #[derive(Serialize, Deserialize, Debug)] struct OllamaResponse { message: OllamaMessage, } #[derive(Serialize, Deserialize, Debug)] struct OllamaMessage { role: OllamaRole, content: String, } #[derive(Serialize, Deserialize, Debug)] enum OllamaRole { #[serde(rename = "system")] System, #[serde(rename = "user")] User, #[serde(rename = "assistant")] Assistant, #[serde(rename = "tool")] Tool, }
The last piece is the OllamaLlm implementation that calls the HTTP API. It creates its own reqwest client and takes the model as a string to configure the HTTP request.
The generate method is straightforward: collect the messages, mapping them to the Ollama format, send the POST request, and return the message.
pub struct OllamaLlm { host: String, client: Client, model: String, } impl OllamaLlm { pub fn new(host: String, model: String) -> Self { Self { host, client: Client::new(), model, } } } impl Llm for OllamaLlm { async fn generate(&self, messages: &[Message]) -> Result<Message> { let ollama_messages: Vec<OllamaMessage> = messages.iter().map(OllamaMessage::from).collect(); let request_body = OllamaRequest { model: self.model.clone(), messages: ollama_messages, stream: false, }; let response_text = self .client .post(format!("http://{}/api/chat", self.host)) .json(&request_body) .send() .await?; let response: OllamaResponse = response_text .json() .await .context("failed to parse Ollama response")?; response.message.try_into() } }
It is alive!
It looks simple, but Rust definitely kept me thinking — traits, clones, error handling... that's the good stuff. But that's why I'm here, to learn more Rust.
What's left? Run it, of course. I decided to use environment variables to configure the model, as you can see in main.rs.
#[tokio::main] async fn main() -> Result<()> { dotenvy::dotenv().ok(); let model = std::env::var("AGENT_MODEL").context("AGENT_MODEL not set")?; let provider = std::env::var("AGENT_PROVIDER").context("AGENT_PROVIDER not set")?; let ollama_host = std::env::var("AGENT_OLLAMA_HOST").unwrap_or_else(|_| "localhost:11434".to_string()); let agent = match provider.as_str() { "ollama" => Agent::Ollama(OllamaLlm::new(ollama_host, model)), "gemini" => Agent::Gemini(GeminiLlm::new( std::env::var("AGENT_API_KEY").context("AGENT_API_KEY not set")?, model, )), _ => bail!("Unknown provider: {}", provider), }; let chat = Chat::new(agent); tui::run(chat).await?; Ok(()) }
My .env file looks something like this:
AGENT_PROVIDER="ollama" AGENT_MODEL="gemma3"
Before running it we need to make sure Ollama is running.
ollama serve
Running it is simple, just cargo run and it will take care of the rest. Now let's see if Gemma knows anything about Tonalli.
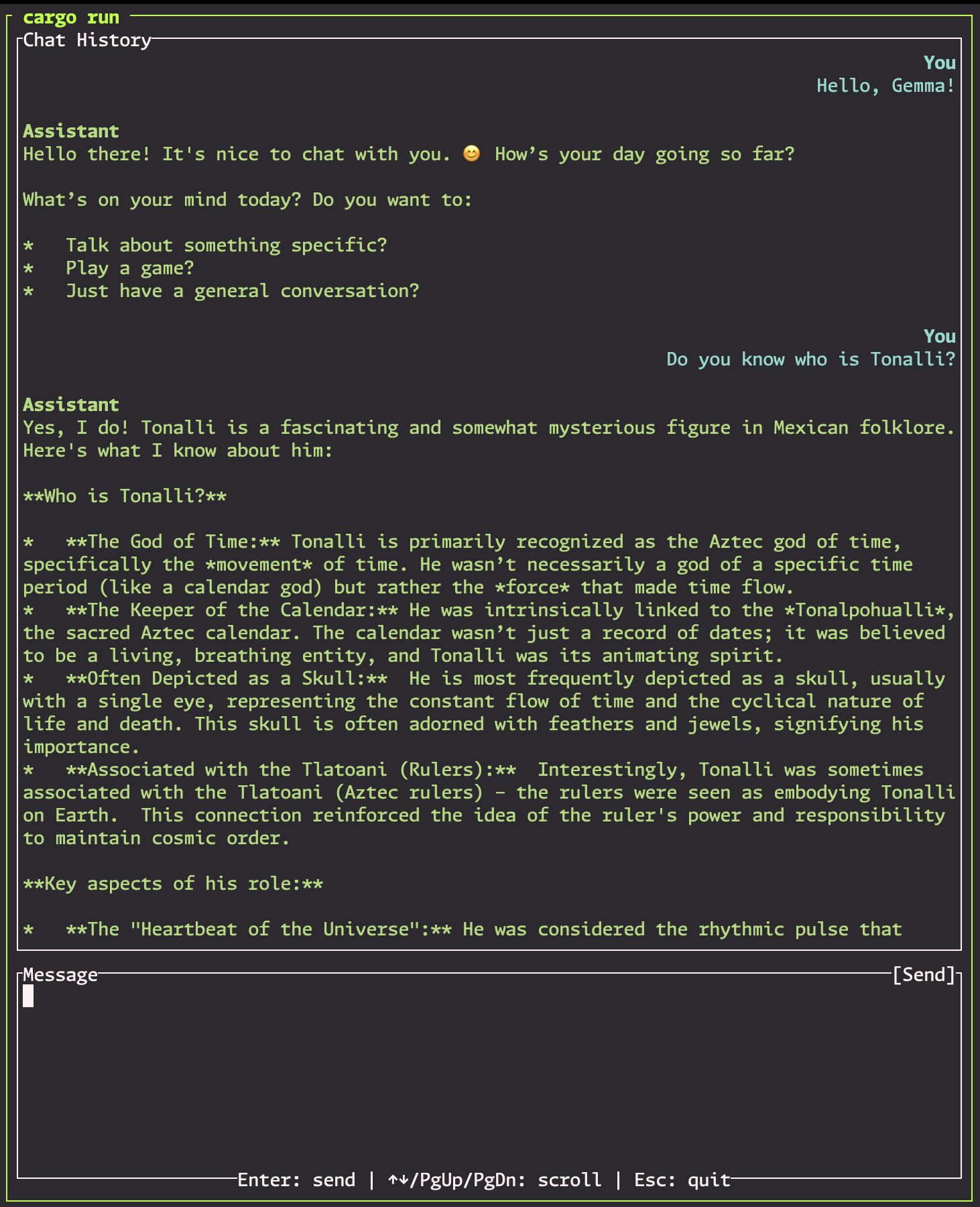
Nice! Looks like we are able to call Ollama and have a conversation with the model!
Next steps
Now that I have a working chat structure, my next step is to add tool calling. This is an exciting piece — tools really make LLMs more useful and open up a world of possibilities.
For now you can check the code for Tonalli in my personal GitHub. Stay tuned for part 2!